 论坛广场
论坛广场 bug反馈
bug反馈 使用教程
使用教程 问题解决
问题解决 意见建议
意见建议 认证申请
认证申请 更新记录
更新记录 官方APP
官方APP 开发者
开发者 问答测试
问答测试 测试论坛
测试论坛 公告说明
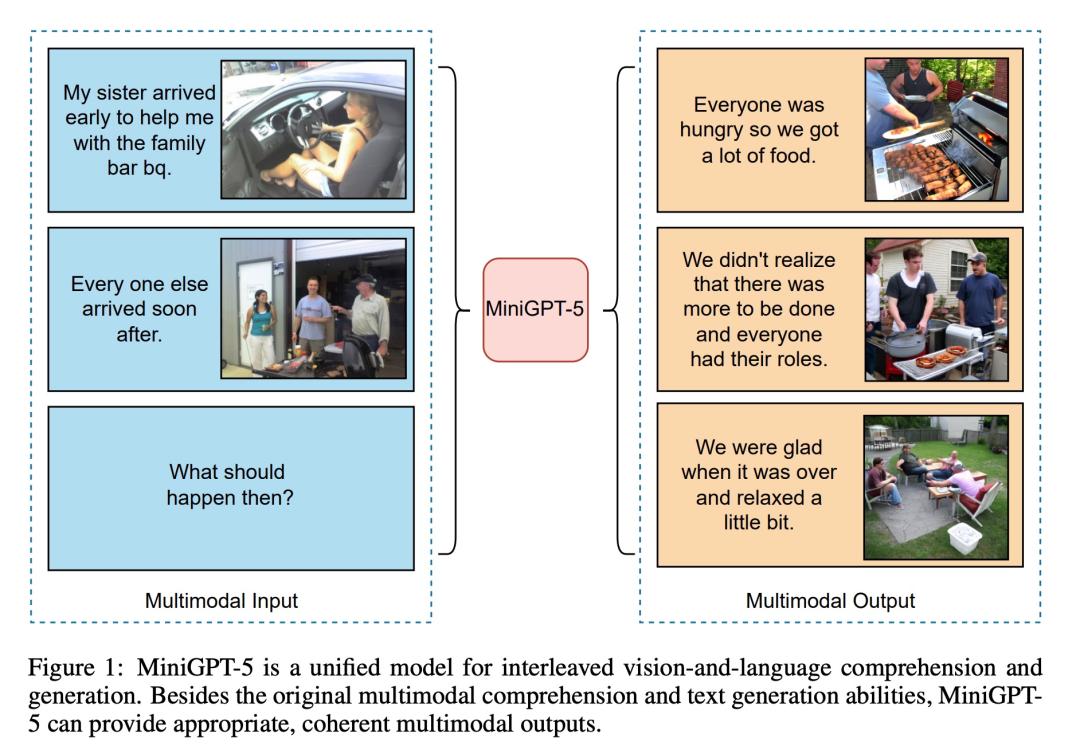
公告说明OpenAI 的 GPT-5 大模型似乎还遥遥无期,但已经有研究者率先推出了创新视觉与语言交叉生成的模型 MiniGPT-5。这对于生成具有连贯文本描述的图像具有重要意义。
通过特殊的视觉 token「生成式 voken」,将 Stable Diffusion 机制与 LLM 相结合, MiniGPT-5 为熟练的多模态生成预示了一种新模式。同时,本文提出的两阶段训练方法强调了无描述基础阶段的重要性,使模型在数据稀缺的情况下也能「茁壮成长」。该方法的通用阶段不需要特定领域的注释,这使得本文解决方案与现有的方法截然不同。为了确保生成的文本和图像和谐一致,本文的双损失策略开始发挥作用,生成式 voken 方法和分类方法进一步增强了这一效果。
统一图像和文字生成的MiniGPT-5来了

广东·广州





请登录之后再进行评论